接触GraphQL是因为暑假实验室项目的接口采用该规范,遂学习一下,基于koa写了一个简单的graphql规范的服务端应用程序,代码扔在Github了(不小心把自己mongoDB数据库的连接密钥也push上去了,不过是MongoDB免费提供的,无所谓了懒得revert)
预备知识
由于笔者没有系统的学习过后端,更没有什么工程经验,这部分内容很多都是自我感受,读者仅供参考,欢迎评论指正。
无论是GraphQL还是REST,都是客户端如何从服务端获取数据的一种规范,下面一张图描述了一个单体服务的应用架构(自己画的,欢迎指正(ฅ•﹏•ฅ)):
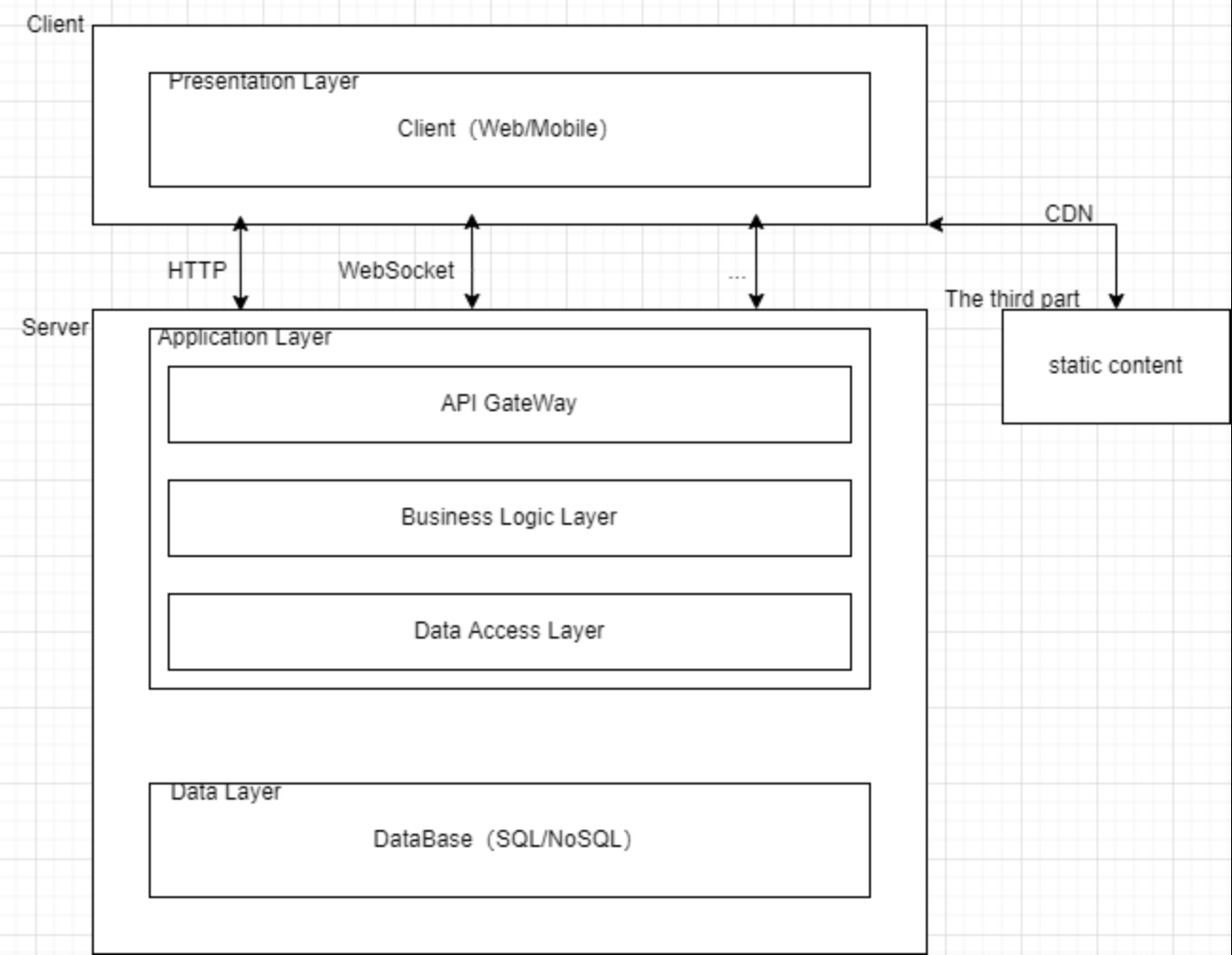
一个应用的数据一般都存储在数据库中,服务端想把数据传输给客户端,首先要从数据库获取数据(一般都是在同一主机上,获取过程可能类似于磁盘读取(未深究),当然,对于多服务架构,一个服务的数据可能来自另一个服务,也即另一台主机的数据库...)。
客户端和服务端基本都不在同一主机上,不同主机之间的数据传输需要网络通信,常见的有:HTTP,WebSocket,gRPC....
基于这些内容,下面看看什么是REST?GraphQL?
REST
上面说过客户端与服务端通信协议有很多,但是REST是基于HTTP的很多特性设计的一种规范(REST的设计者曾参与HTTP协议规范的制定,
算是夹带私货??)
比较常见的规范如下:
- URL定位服务端资源(也就是数据),HTTP动作(GET/POST/PUT/DELETE)来操作资源
- 使用HTTP Status Code表示服务器状态
HATEOAS,通俗来讲就是:客户端事先对于服务端能提供怎样的数据一无所知,仅知道两者之间交互的URL( 专业点叫hypermedia,restful教旨中资源的表现形式,我理解为URL)
具体表现在指导后端开发人员如何设计接口及编写应用程序,示例如下:
1 | 表示某个用户user的朋友列表信息: |
后端的应用程序在处理时,也是关注URL和请求的方法,再给出返回的数据
1 | import Koa from "koa"; |
但是据我目前所了解,很多公司并没有严格遵循REST的设计规范,主要在于REST设计时有点理想化,很多HTTP的设计并没有为实际开发的业务考虑,具体表现在:
- 不使用HTTP Status Code表示服务器状态,而是全部返回200,自己在返回的数据中增设code字段表示服务器内部业务处理逻辑的状态。
- 不使用PUT/DELETE,基本上全部使用POST请求事先。
关于这两种情况,可以翻看知乎的相关讨论:
为什么那么多公司做前后端分离项目后端响应的 HTTP 状态一律 200?
GraphQL
不同于REST和HTTP协议的强关联性,GraphQL具有
transport-layer agbostic的特点,也即客户端与服务端之间的通信协议使用什么都无所谓...
先来大概看一下graphql规范下客户端和服务端的处理过程。
客户端可以选择多种通信协议与服务端进行通信,下面均以HTTP协议为例:
1 | curl -X POST \ |
从上可知,我们向http://localhost:4000/graphql发送一个POST请求,传送一个query字符串,不同于REST,url不再对应于一个资源,而是代表graphql应用程序的入口,也即客户端向服务端请求任何数据均通过该URL进行。
服务端应用程序在乎的仅仅只是query字符串。服务端会如何处理该query字符串呢?在服务端眼里,会得到这么一个东西: 1
2
3
4
5query {
person {
name
}
}
query下要查询的fields是person,其内部又嵌套了一个name的fields,graphql 服务端应用程序为每一个fields提供了一个resolver函数,用于获取该字段对应的数据库数据
The execution starts at the query type and goes breadth-first.
也即我们先执行person的resolver函数,获取之后再进入它的子级字段,执行他们的resolver函数。值得一提的是,如果某个字段的resolver是个异步函数(一般会是一个Promise对象)那么resolver能够感知到Promise的进度,并会等待它执行完返回结果之后才会进行子级字段的查询。(因此这个环节注意异步处理上的优化。)
大概了解之后再来系统说一下GraphQL的优劣,优点:
- Graphql能够减少网络请求次数(相比于REST),因此速率会更快
- 简单来说就是能够聚合多个REST请求为一次网络请求
- 适合多系统和微服务结构
- 由graphql的设计决定,其可以很容易统一多个服务的接口,并向外暴漏graphql式的接口(做API Gateway)
- 不存在over-fetching 和under-fetching的问题
- 类型定义(Schema的重要作用,具体见下文),优势可体现在:
- 客户端进行请求时,会检测query字符串中数据结构的合理性
- 服务端返回数据时,返回的数据结构就是query字符串查询的数据结构(just like SQL),而REST,客户端完全不知道返回的数据结构会如何
- 适合项目的快速迭代
- 对于REST,需要废弃并更改新增很多接口,同时前端也需要更改相关的业务代码
- 对于graphql,只需要后端新定义相关的fields并补充resolvers,前端不需要任何更改
缺点:
- graphql查询细节问题会很难事先,具体表现在:
- 限制客户端的查询层级深度
- 权限设置等等
- graphql的缓存问题
- 这在REST中十分简单(因为HTTP本来就支持对于URL的缓存)
- 但在GraphQL中只有一个URL,不能采用原本HTTP的缓存方案
- 网络速率限制
- REST中可以较为容易的实现一天内对某个URL的访问次数限制
- GraphQL中就比较麻烦...
Koa(GraphQL)
这里主要说一下我认为比较重要的,也就是Schema的定义(对详细代码感兴趣的可以看文章开头的github地址)
Schema是GraphQL的核心,服务器的核心代码就是围绕Schema实现的,它描述了客户端能从服务端获取什么数据(和遵循HATEOAS的REST形成鲜明对比)
schema.js(schema定义文件): 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20const RootQuery =new GraphQLObjectType({
name:"RootQueryType",
fields:{
person:{
type:PersonType,
args:{},
resolve(parent,args){
return Person.find({}).then(
res=>{
return res[0];
})
}
}
}
})
const schema =new GraphQLSchema({
query:RootQuery,
mutation:RootMutation
})
export {schema}app.js(服务端应用程序入口): 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import Koa from "koa"
import { graphqlHTTP } from "koa-graphql";
import mount from "koa-mount"
import {schema} from "./graphql/schema.js"
import { ConnectDB } from "./database/index.js";
const app =new Koa();
ConnectDB();
app.on('error',(err)=>{
console.log("Server err:",err)
})
app.use(mount('/graphql',graphqlHTTP({
schema:schema,
graphiql:true
})))
app.listen(4000,()=>{
console.log("The Server is listening at 4000!!")
})
Apollo
找时间学习一下Apollo.....
to be continued
吃完饭再写....
参考链接
- 怎样用通俗的语言解释REST,以及RESTful?--知乎
- HATEOAS --wikipedia
- Graphql 官网
- How to GraphQL
- GraphQL Advantages and Disadvantages
- How to set up a powerful API with GraphQL, Koa, and MongoDB
补充链接
在写这篇文章时,也查阅了一些关于HTTP缓存的知识,特此补充一下