其实本人对算法没什么兴趣,但是担心这学期面试中遭不住气宗面试官的追问(心里没点B树怎么敢投简历)
于是就打算先回顾一下大一下学期学的数据结构,为以后的各种算法打好基础...
图文无关(此OI非彼OI...) 
How to Learn ??
知乎上有一篇高赞回答,感觉说的挺不错的,分享一下
简单来讲,就是任何数据结构都是在已有数据结构上因为一些新的需求发展起来的,因此学习数据结构时不要割裂不同数据结构之间的关系,多去思考不同的数据结构之间的异同和联系...
而无论是什么数据结构,都是内存中数据的一种组织形式,那么首先就要了解我们平日写的代码中的数据在内存中是如何存储并管理的....
Secret of Memory ??
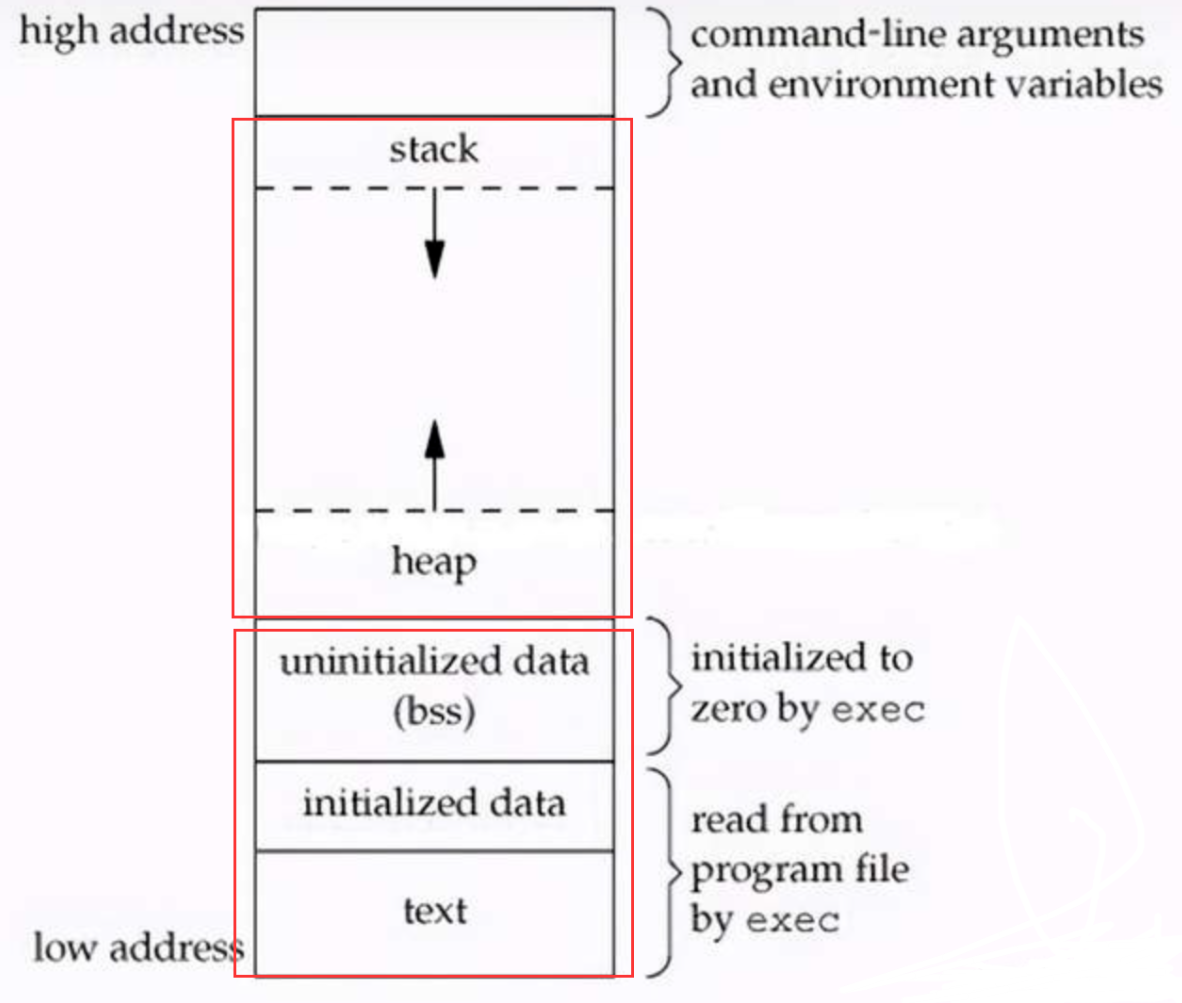
我们这里说明一下进程的内存分配情况
当我们要运行写好的代码时(先链接编译为可执行的二进制文件过程就不说了...),操作系统会create一个进程,并在内存中为其分配相应的空间。
进程由三部分组成:PCB,数据段和程序段。
其中PCB是一个存储在内核空间的task_struct结构体。
我们平时写代码时,代码段内声明的变量会存放在进程的程序段地址内,其中已经声明了的放在程序段的Data段内,未声明的会放到BSS段内(执行之前会被内核初始化为0或null)
而代码运行过程中产生的变量等会被存放到数据段,数据段又分为stack和heap两段区域,其中:
- Stack:存储局部、临时变量,函数调用时,存储函数的返回指针,用于控制函数的调用和返回。在程序块开始时自动分配内存,结束时自动释放内存,其操作方式类似于数据结构中的栈。
- Heap:存储动态内存分配,需要程序员手工分配,手工释放(具有内存回收机制的语言不需要手动分配和释放,比如JavaScript)注意它与数据结构中的堆是两回事。
Basic Type of Data
先介绍一下基础的数据类型,这里以C语言为例
C语言真正称得上基本类型的是short,int,long,char,float,double。
这里就简单说一下char类型,占用1 Byte,值是使用单引号(Python和JavaScript写多了就容易忽略这一点)包裹的一组字符
除此之外,还有空类型(void),枚举类型(enum)和派生数据类型(array,struct,union)
enum:一组整型值的集合,和宏很相似,只不过:
enum在编译阶段将名字替换为对应的值,宏是在预处理阶段将名字替换为对应的值。
1 | enum Test { |
array类型其实并不存在(这里只是用该符号说明一种数据类型) 1
2// define Array: [type] VariableName [ArraySize];
int Test[10];
JavaScript的数组变量不需要在声明时指定大小,贺老的回答,里面这样说的:
从这个历史源头来说,JS的数组只是稍微魔改一下的对象,而对象就是一个属性包,并不基于连续存储,也就不存在数组容量概念。
不过也正因为C语言数组需要预先确定大小,所以无法用于动态增长的数据,也就引入了链表这一结构的出现。
c语言的数组只能存储相同类型的一组变量,struct提供给我们储存各种类型变量的能力。 1
2
3
4
5
6
7
8struct StructName {
int TestNumber;
char TestName;
...
} Variable;
// 访问结构体成员
printf("%c\n",Variable.TestName);
结构体成员变量的首地址要能被该结构体中最宽的成员的大小整除
结构体成员相对结构体首地址的偏移量(offset)都是本成员大小的整数倍,如有需要编译器会在成员之间加上填充字节;
结构体的总大小为结构体最宽成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节
Union类型和Struct很像,不同点在于内存的分配上,struct中的变量均拥有自己的内存(可能会因为对齐规则存在空隙),而Union中的变量共用同一块内存,一个Union变量所占内存大小为最大的成员变量所占内存。(到现在就没有用过Union,也就不多数什么了...)
Advanced Type of Data
下面介绍一下在这些基础数据结构上延申出来的数据结构(我自己想叫他们为高级数据结构...)
LinkList
链表是这些高级数据结构的基础,其他高级数据结构大多数在链表的基础上进行各种变换演变而来....
以C语言为例,默认的数据结构无法管理动态的数据,数组所管理的一组数据也必须要事先声明大小。因此,为了管理动态的数据引出了链表的设计。
所以链表是什么呢?其实就是一串结构体,每个结构体有一部分用来存数据,再设置一个变量存储下一个结构体的内存地址,对于一组动态数据,我们可以通过malloc函数来动态的申请内存然后再将其添加到链表上。
下面简单演示一下,需要管理的动态数据就是从0开始的自然数,但是到几不知道.... 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29// 声明结构体
struct node {
int data; //需要管理的动态数据
struct node *next;
};
int main(void){
// 初始化头结点
struct node *head =(struct node *)malloc(sizoeof(struct node));
head->data =0; //该数字无意义
head->next=NULL;
struct node *tail =head;
// 初始化链表(该组数初始为0~100)
for (int i=0;i<=100;i++){
struct node *temp =(struct node *)malloc(sizoeof(struct node));
temp->data =i;
temp->next =NULL;
tail->next =temp;
tail =temp; //更新尾节点...
}
// 如果数继续往上加,那就申请地址,再挂载到链表上即可
struct node *temp =(struct node *)malloc(sizoeof(struct node));
temp->data =101;
temp->next =NULL;
tail->next =temp;
tail =temp;
return 0;
}
这里思考一下链表的指针:
链表的关键就在于通过指针链接分散于内存中各个位置的struct,因此我们只需要链表的头结点的地址,然后就能通过指针管理链表上各个结构体。
链表的出现完美解决了动态数据的管理问题,但是貌似并不是最优的,比如我想要在链表末尾插入一个结构体,就需要先从头遍历到尾再进行 操作,时间复杂度为
解决这个问题可以设置双指针,然后记录头尾结点的地址进行链表的管理。但是对于中间结点的修改和插入仍需要遍历,时间复杂度并没有下降,有没有什么方法能降低时间复杂度呢?
我们知道无序数组查找某个元素时时间复杂度为O(n),但是有序数组通过二分法查找时间复杂度就会降低到:
计算过程: n代表数组长度,k代表循环次数,由于循环结束时的查找区间为1,可知:
计算过程挺简单的,这里主要是测试一下博客的latex渲染...~
链表可不可以进行类似的改进让其有序,从而进行二分查找以减少遍历的时间复杂度呢?由此引出了二叉排序树。
上面是从时间的角度优化链表,下面我们从空间的角度考虑一下,链表引入了指针占用了额外的内存,对于一个存储着整形数值的链表来说内存是数组的两倍,如何改进?由此引出了堆。
Binary tree
二叉树属于树的特殊结构,每个结点只有两个子节点。
二叉树是一个很重要的数据结构,不仅是链表和数组的延申,又可以作为图的基础。
1 | //二叉树的数据结构(c) |
二叉树又细分为很多类型:
- 二叉排序(搜索/查询)树
- 特点:左子树上所有结点的值均比根节点小,右子树上所有结点的值均被根节点大
- 完全二叉树
- 特点:只有最下面的两层结点度小于2,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树。
- 满二叉树
- 特点:所有结点(叶结点除外)的度都是2,满二叉树一定是完全二叉树,反之不一定
- 平衡二叉树(AVL)
- 特点:树的左右子树的高度差不能超过1
- 应用:二叉树在插入元素时,如果随便插入,很可能
偏的很厉害,最特殊的情况:每次都插到左子树,最终使其发展为链表,从而影响二叉树的查询效率
- 红黑树:
- 特点:含有红黑结点并能自平衡的二叉查找树
- 哈夫曼树:
- 特点:又称最优二叉树,是一种带权路径长度最短的二叉树,所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度
- B树:
- 特点:B树属于多叉树又名平衡多路查找树(查找路径不止两个)
- 应用:数据库的索引技术多使用该数据结构
- B+树:
- 特点:是在B树的基础上又一次的改进,其主要对两个方面进行了提升,一方面是查询的稳定性,另外一方面是在数据排序方面更友好。
- ...
上述内容暂时写的十分笼统,主要是先有个大致概念,后面再展开详细学习...
Heap
堆就是用数组实现的二叉树,所以它没有使用父指针或者子指针。因而节省了内存空间
堆主要有两类:最大堆和最小堆,区别在于结点的排序方式,最大堆中父节点的值比每一个子节点都要大,最小堆反之。
前面说过堆就是用数组实现的二叉树,下面主要将堆和二叉树进行对比:
- 结点的顺序问题,一定要区分最大(小)堆和二叉排序树之间结点大小关系
- 堆由于通过数组实现,比二叉树相比少了指针占用的内容空间
- 平衡性,前面说过二叉树想要保持
O(logN)的良好性能需要满足平衡性,但在堆中只要满足堆属性就能保持平衡性 - 搜索性能不如二叉树,因为堆结构不将其视作第一优先级,但是堆结构可以快速的找到集合中的最大或最小值。
堆结构一般使用数组实现,如下所示(一个最大堆): 1
let MaxHeap =[10,7,5,2,3,4,4]
1
2
3
4
5//索引为i的结点的父节点的索引:
parent(i) =Math.floor((i-1)/2)
//索引为i的结点的左右子节点的索引
right(i) =2i+1
left(i) =2i+2
说到这里,其实堆就是一个特殊的数组,不同索引对应的值满足特定的关系,也正因如此,我们往堆中添加/插入/删除元素时,需要按照该规则插入。
下面给出堆的定义以及相关方法实现 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58class MaxHeap{
constructor(list){
this.heap =[];
this.init(list) //初始化heap
}
// 创建一个最大堆
init(list){
for(let i=0;i<list.length;i++){
this.insert(list[i])
}
}
// 向堆中添加元素
insert(val){
this.heap.push(val);
let len=this.heap.length-1;
while(len>=0 && this.heap[parseInt((len-1)/2)]<this.heap[len]){
// 交换位置
let t =this.heap[len];
this.heap[len] =this.heap[parseInt((len-1)/2)];
this.heap[parseInt((len-1)/2)] =t;
len =parseInt((len-1)/2)
}
}
// 删除根结点(一般对堆的删除操作均指删除根结点)
/**
* 根节点删掉之后,需要重新选择根节点,如何选取呢?
* 堆一定是一个完全二叉树,因此把数组最后一个元素作为头结点即可。
* 但是此时堆上结点不一定满足堆属性,需要进行修改
* 删除根节点之后并将末尾元素补上之后只有**顶三角可能不满足堆属性**
* 因此首先是将顶三角满足,比如右子结点或左子节点换上去,那么换下去的跟结点所在的三角可能不满足
* 故这样一直换,直到换到子节点即可
*/
delete(){
this.heap[0] =this.heap.pop();
let len=this.heap.length-1;
let i=0;
while(
(2*i+1<len || 2*i+2<len) &&
(this.heap[2*i+1]>this.heap[i] || this.heap[2*i+2]>this.heap[i])
){
// 判断被哪个子节点被换上去
let mi,mt;
mi =(this.heap[2*i+1]>this.heap[i]) ? (this.heap[2*i+1]>this.heap[2*i+2] ? 2*i+1:2*i+2) :2*i+2
mt =this.heap[mi];
this.heap[mi] =this.heap[i];
this.heap[i] =mt;
i =mi; //更新i
}
}
// 返回堆中最大值
peek(){
return this.heap[0]
}
}
参考链接
- Heap --github
- ...
To do
每个数据结构的定义- 每个数据结构的优势,用途
- 每个数据结构相关的应用(OI题)
- 后续单独写篇文章补充吧...
慢慢来....